해시 인덱스의 한계를 깨는 인덱스 구조를 살펴보자.
SS 테이블 및 LSM 트리
그림 3-3에서 로그 구조 메모리 세그먼트는 일련의 키-값 쌍입니다.
다음은 키-값 쌍 세트입니다. 키로 정렬해보자. 이 형식 정렬된 문자열 테이블 또는 SS 테이블 그것은이라고.
장점
- 세그먼트가 정렬되기 때문에 병합, 정렬그만큼 가능한하다.
- 특정 키를 찾기 위해 메모리의 모든 키지수 잡을 필요가 없다. 이미 정렬되어 있기 때문에 키 B의 오프셋을 모르면 A와 C의 오프셋 위치만 알면 중간에 B를 찾을 수 있습니다.
- 읽기 요청은 이러한 레코드를 보냅니다. 블록으로 압축할수있다. 디스크 공간을 절약하고 I/O 대역폭 사용량을 줄일 수 있습니다.
정렬된 구조를 디스크에 유지하는 것이 가능하지만 메모리에 유지하는 것이 훨씬 쉽습니다.
임의의 순서로 키를 삽입하고 정렬된 순서로 해당 키를 읽는 프로세스
쓰다: ‘메모리 테이블(in memory)을 균형 트리 데이터 구조에 추가 → 메모리 테이블이 임계값보다 커질 때 SS 테이블 파일로 디스크에 쓰기(트리가 이미 키별로 정렬되어 있으므로 효율적임)
읽다: ‘메모리 테이블에서 키 찾기 → 디스크의 최신 세그먼트에서 찾기’
(배경) 가끔 병합 + 응축 과정을 밟다
그러나 memtable에 쓰는 과정에서 데이터베이스가 실패하면 memtable에 쓴 데이터가 손실됩니다.
그러므로 ‘별도의 쓰기 데이터(로그 파일)를 디스크에 보관 → 디스크에 메모리 테이블을 SS 테이블로 저장 → 로그 파일을 디스크에서 제거‘ 데이터 손실을 방지합니다.
LSM 트리
위와 같이 SS 테이블 형태로 디스크의 키-값 데이터 인덱스 저장LSM 트리라고 합니다. LSM 트리의 기본 아이디어는 백그라운드에서 체인의 SS 테이블을 병합하는 것입니다. 데이터를 정렬하여 저장하면 범위 쿼리를 효과적으로 줄일 수 있습니다.
LSM 트리의 성능을 최적화하는 방법
1. 블룸 필터 추가
– LSM 트리 알고리즘은 데이터베이스에 존재하지 않는 키를 찾습니다. 느려질 수 있습니다 (메모리 테이블을 확인하고 가장 오래된 세그먼트로 돌아가야 합니다.)
– 이 경우 Bloom 필터를 추가하면 해당 키가 데이터베이스에 존재하지 않는다는 것을 알 수 있습니다.
2. 크기 계층 압축 및 레벨 압축
SS 테이블을 압축하고 병합하는 순서와 시기를 결정하기 위한 전략
- 크기 단계 압축(단계별 압축)
– 새롭고 더 작은 SS 테이블을 더 오래되고 더 큰 SS 테이블과 병합
- 레벨 다짐(평준화된 압축)
– SS 테이블은 여러 레벨로 나뉘며 레벨이 높아질수록 테이블의 크기가 커집니다.
– 비교적 오래되고 큰 SS 테이블과 더 작고 새로운 SS 테이블을 연속적으로 병합합니다. 한 레벨의 SS 테이블 파일 간에는 키가 겹치지 않으므로 레벨 수만큼 쿼리하면 데이터를 찾을 수 있습니다.
B트리
LSM 트리 인덱스가 보편화되고 있지만, 여전히 가장 널리 사용되는 인덱스 구조B트리이다.
LSM 트리 및 B 트리 함께
- 정렬된 키-값 쌍을 유지하므로 범위 쿼리에 효율적이라는 점을 제외하면 유사합니다.
LSM 트리 및 B 트리 차이점
- LSM 트리는 데이터베이스를 가변 크기의 세그먼트로 나누고 순차적으로 기록합니다.
- B-트리는 고정된 크기(4KB)의 블록 또는 페이지로 나뉘며 한 번에 한 페이지씩 읽고 씁니다.
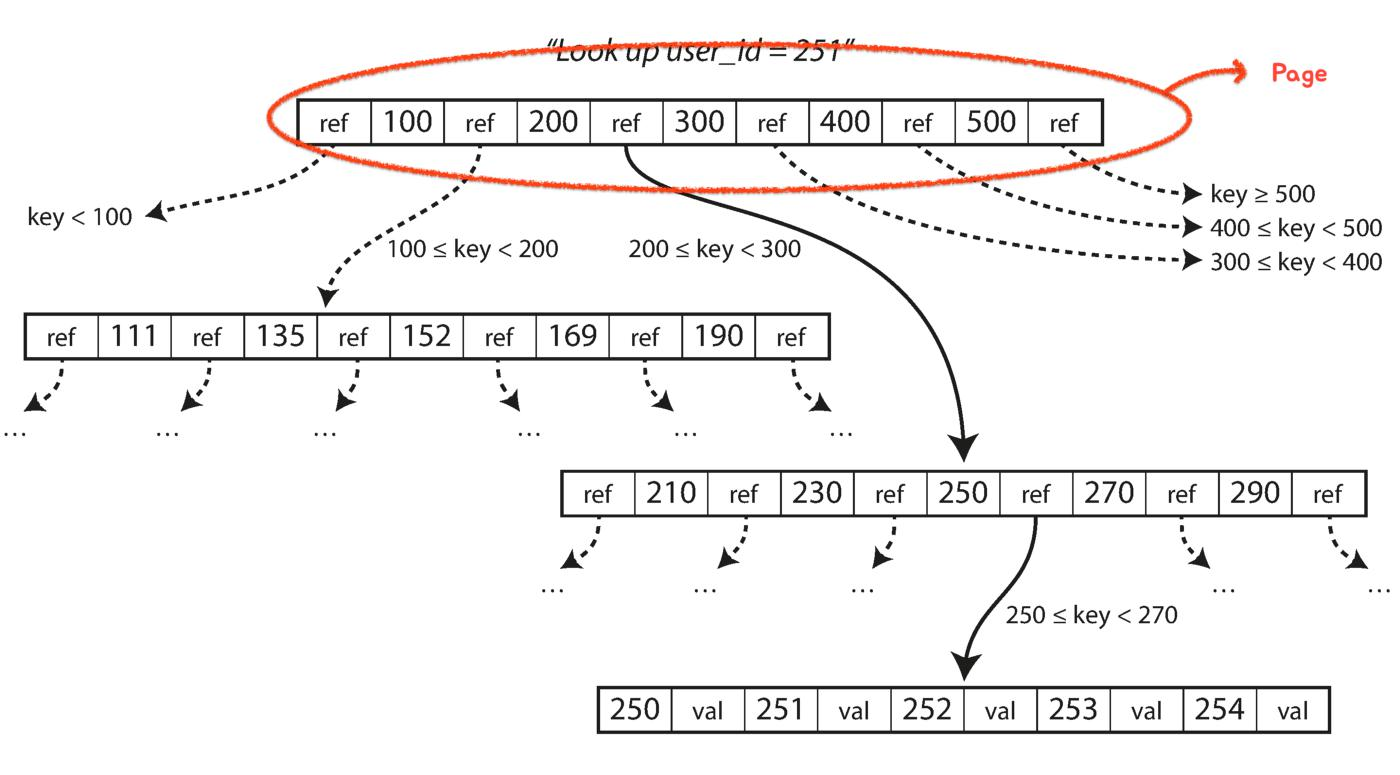
B트리는 워드트리와 같이 최상위에 위치 마스터 페이지그리고 루트 페이지에서 참조된 몇 가지 리프 페이지각 페이지는 하위 페이지의 주소(ref)를 가지며 하위 페이지에 대한 링크 수를 세는 것으로 구성됩니다. 분기 인자그것은 말한다. 인덱스에서 키를 찾으려면 루트 페이지에서 시작하십시오.
B-트리에서 키 값을 어떻게 업데이트합니까?
해당 키가 포함된 리프 페이지 가져오기 → 페이지에서 해당 키 값 바꾸기 → 해당 페이지를 디스크에 다시 쓰기
B-트리에 키를 어떻게 추가합니까?
새 키의 범위인 페이지 찾기 및 추가
페이지에 새 키를 추가할 여유 공간이 없는 경우 기존 페이지를 두 페이지로 분할하고 해당 두 페이지를 가리키도록 상위 페이지를 업데이트합니다.
⇒ 균형잡고 있다
신뢰할 수 있는 B-트리 구축
B-트리의 쓰기 작업은 디스크의 페이지를 새 데이터로 덮어씁니다.
B-Tree 제약 조건 및 솔루션
- 고아 페이지의 발생
- 삽입이 많은 페이지 분할에서 데이터베이스가 충돌하는 경우 부모 관계가 없는 고아 페이지가 발생할 수 있습니다.
- ⇒ 하드디스크 쓰기 전 로그(WAL = 복구 로그)모든 B-트리 변경 사항을 기록합니다. 데이터베이스가 복원될 때 B-트리를 일관된 상태로 복원하는 데 사용됩니다.
- 다중 스레드 액세스를 위한 동시성 제어
- 여러 스레드가 있는 동일한 페이지를 새로 고치면 일관성이 깨질 수 있습니다.
- ⇒ 잠그다(잠그다)(가벼운 잠금) 트리의 데이터 구조를 보호합니다.
B-트리 최적화 기법
- WAL(Log-Before-Write) 대신 일부 데이터베이스는 쓰기 위해 복사(기록 중 복사) 사용됨. 변경된 페이지를 다른 위치에 쓰고 변경된 자식 페이지를 참조하기 위해 새로운 버전의 부모 페이지를 생성하는 방법입니다.
- 웹 사이트상에서 축약 키이것은 공간을 절약할 수 있습니다.
- 일반적으로 페이지는 디스크의 어느 위치에나 있을 수 있지만 영역 스캔에는 비효율적입니다. 따라서 B-트리 구현은 리프 페이지가 디스크에서 가능한 한 연속적으로 나타나도록 시도합니다. (+ LSM 트리는 세그먼트를 병합하는 동안 디스크에 세그먼트를 다시 기록하므로 키를 서로 가까이에 쉽게 배치할 수 있습니다.)
LSM 트리와 비교
LSM 트리는 쓰기 속도가 더 빠르고 B-트리는 읽기 속도가 더 빠릅니다.
LSM 트리 이점: 쓰기 성능 비용
B-트리 인덱스는 로그인 후 작성해주세요그리고 나무 쪽한 번 기록해야 합니다. LSM 트리는 SS 테이블의 반복된 압축 및 병합으로 인해 데이터를 여러 번 다시 씁니다. (이것은 쓰기로 인해 디스크에 여러 번 쓰기가 발생하는 경우 발생합니다. 쓰기 강화라고 합니다.)
그러나 LSM 트리는 B 트리보다 낫습니다. 쓰기 게인이 낮음 여러 페이지를 덮어쓰는 대신 SS 테이블 파일 순차쓰기 처리량은 B-트리보다 높습니다.
LSM 트리 이점: 압축률
LSM 트리는 좋은 압축률 B-Tree 대신 디스크에 더 적은 수의 파일 만들기Tun.LSM 트리는 페이지 지향적이지 않고 조각화를 제거하기 위해 주기적으로 SS 테이블을 다시 쓰기 때문에 메모리 오버헤드가 낮습니다.
LSM 트리 단점: 압축 성능 예측 어려움
LSM 트리 압축 프로세스는 때때로 진행 중인 읽기 및 쓰기 성능에 영향을 미칩니다. 디스크가 비용이 많이 드는 압축 작업을 수행하는 동안 요청을 기다려야 할 수 있습니다. 반면에 B-tree의 성능은 예측하기 쉽습니다.
LSM 트리 단점: 높은 압축 쓰기 처리량
빈 데이터베이스에 쓸 때 모든 디스크 대역폭은 초기 쓰기에만 사용할 수 있지만 데이터베이스가 커짐에 따라 압축~을 위한 더 많은 디스크 대역폭 필요하다.
B-트리 장점: 동시성 제어
B-트리에서 각 키는 인덱스의 정확히 한 위치에 존재합니다. 반면에 LSM 트리는 서로 다른 세그먼트에 동일한 키의 여러 복사본을 가질 수 있습니다. 이러한 측면은 B-트리를 강력한 트랜잭션 의미 체계를 제공해야 하는 데이터베이스에 훨씬 더 매력적으로 만듭니다.